
String Procedures - Extracting a Sub-String
Contents
String Procedures - Extracting a Sub-String#
Now let’s apply what has gone before to our ultimate project - searching the web.
What Is a Uniform Resource Locator Anyway?#
Uniform Resource Locator (URL) is a text string that specifies where a resource (such as a web page, image, or video) can be found on the Internet. [MDN, 2022]
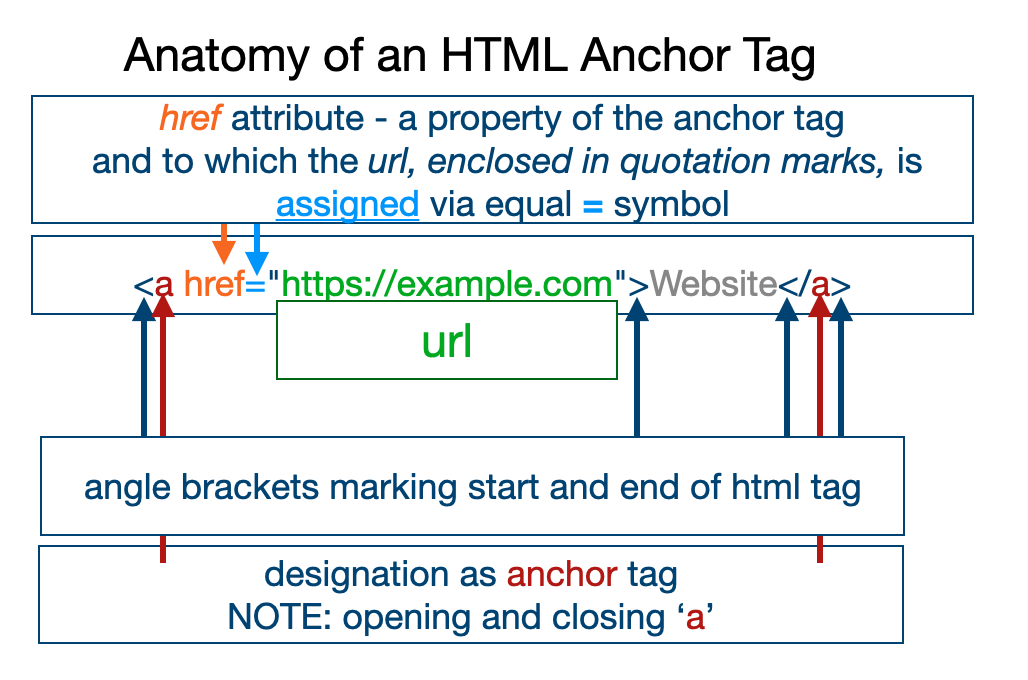
But the url is embedded in an html element called the anchor element with the syntax
<a href="https://example.com">Website</a>
and the following structure
Our task will be to find the links on the page and use their url attributes.
But before we tackle that, let’s come up with a method that combines the string-related tools we’ve covered so far and allows us to extract a substring such as the url embedded in a link.
Practice Parsing an IPv6 Address#
Background#
When you visit a web site, the url goes by a name — e.g., google.com, brave.com, youtube.com. However, underlying those names is a numbered address recognized by domain name servers around the world.
Currently, all computers accessing the internet, whether as client or server, have an IP address that is associated with the name address.
Thus, one of IP addresses associated with google.com is 142.250.191.132. In fact, you can enter that address in your browser instead of google.com, and you’ll be directed to the latter.
The current dominant protocol is IPv4 (internet protocol version 4) but the world is trying to move to IPv6 for a number of reasons, not least of which the IPv4 addressing system is exhausted. Whereas IPv4, with a 32-bit space, provides 4,294,967,296 addresses, IPv6, weighing in at 128 bits, provides an address space of about 3.4 x 10\(^{38}\) addresses.
Colon-Hexa Representation in IPv6#
To be more precise, an IPv4 address is 4 8-bit numbers separated by . periods (e.g., 188.22.33.23), IPv6 addresses consist of 8 groups of 2-byte hexadecimal (i.e., base 16) numbers separated by : colons. Each 2-byte set is called a hextet.
IPv6 address examples might be:
684D:1111:222:3333:4444:5555:6:772001:0db8:0001:0000:0000:0ab9:C0A8:01022345:0425:2CA1:0000:0000:0567:5673:23b5
We’ve said that each address has 8 groups of 2 bytes each using hexadecimal numbering (0 through F). But you’ll note that some of the example addresses only have one or two hexadigits. That’s because the address can be abbreviated when the hextet begins with one or more zeros. Thus, a hextet of 004A can be reduced to 4A.
That’s all by way of saying that when a protocol program (one used to route traffic to and from an IPv6 address location) parses the digits, it must use the colons : to delimit or separate one hextet for another.
A perfect job for Python’s string find() method and string slicing.
Using the : colons as delimiters, we find the first colon, then the second, then the third. We know that between the second and third colons our desired hextet (or slice of the address) falls. Having the second and third colon index positions, we simply slice between the two as shown below.

addr = "684D:1111:2220:33A3:4F9E:2CA1:6:91"
first_idx = addr.find(':')
second_idx = addr.find(":", first_idx + 1)
third_idx = addr.find(":", second_idx + 1)
extracted_hextet = addr[second_idx + 1 : third_idx]
print(extracted_hextet, extracted_hextet == '2220')
2220 True
Returning to the URL and Anchor Tag#
In order to extract the url, we use the same technique or method. We find delimiters and find our way along the string so that we are positioned, using those delimiters, on one side and then the other of the url.